So, you’ve got your Splunk Enterprise up and running and collecting data from some of your systems. A few dashboards have been created too and life is good. But perhaps, there could be more?
Splunk Enterprise license only limits the data you can index per day so scaling the environment and providing better data availability is just a matter installing new Splunk instances. This post will give you hints on what you can do.
Splunk Enterprise scaling
When it comes to scaling Splunk, you can always just add more CPU, memory and storage to be able index more and search faster. This does not however provide any resiliency to your data. All of your eggs are in the same basket and eventually birds will get angry.
Of course, your risk model should define how important the data is to you and introducing a few additional servers might get some kind of resistance from the devops department; new servers cost money and require additional work in form of monitoring and updates, although most of these tasks should be already automated (if not, there’s something to look into and yes, we can help with that).
Even if you have an environment where no new hardware is required, say a vSphere for example, you still might be scared to invest time and consultancy hours for setting up a clustered Splunk Enterprise environment as “there is just oh so much of this and that”. Well, don’t be. Splunk cluster installation is fairly trivial. You can also convert your single-instance Splunk to an Indexer cluster without losing any data.
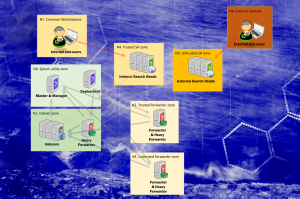
From indexing point of view, it all comes down to selecting between a single instance and an indexer cluster.
Single instance
- Simple to manage
- Scales vertically
- No data resiliency
- Requires only a single server
- Great for starting your Splunk journey
Indexer Cluster
- Requires more management overhead
- Scales horizontally
- Data replicated over multiple servers
- Requires 4+ servers
- Provides a basis for a happy, long lasting Splunk relationship
Splunk Clustering
There are two different types of clusters in the wonderful world of Splunk
- Indexer Cluster
- Search Head Cluster
They serve two totally different purposes and using the other does not require the other one as well.
Clustering Splunk might at first seem very complex. However, initial setup of either of Splunk Clusters only requires a few configuration parameters. It can also be done directly from Splunk Web, but we always modify the configuration files directly to gain better control over the configuration.
So what does a clustered setup bring to your Splunk Enterprise? Simple and important features, such as
- Availability
- Continuity
- Better performance
- Data resiliency
By adding more Indexers to your environment you ensure that your indexed data is distributed among multiple servers (eggs are in multiple baskets and continuity is secured). Replication factor determines the number of servers each bit of data is stored in and can be easily tuned to match your risk model.
Splunk can also be configured to be site-aware, enforcing data replication within an indexer cluster split to different (physical) locations. If you have servers in multiple data centers, multi-site cluster is definetely something to look into as it also allows to use local indexers for data input, while still making all data fully available from the other site as well. You need to calculate the required network and storage capacity though, to be able to efficiently synchronize data between the sites (we have created a simple Excel for that).
Search Head Cluster (SHC) on the other hand, provides more power to your data presentation. It allows you to scale the user visible front end horizontally, providing faster searches and better availability for your service. As you will most likely build a lot of scheduled searches, the SHC will ensure that your searches continue to run even during maintenance or an unforeseen problem, providing any critical alerts from your monitored infrastructure.
Even if you are not initially going to build a Search Head Cluster, it is good practice to put the search head behind a reverse proxy or a load balancer so it can easily be scaled later on without hardly any downtime.
So how many servers are needed exactly?
This depends on the required capacity. Building both a full-scale Indexer Cluster and a Search Head Cluster should contain a minimum of 8 servers
- 3 Indexers
- 3 Search Heads
- 1 Deployer
- 1 Master (also in license master role)
Master and Deployer are management nodes for Indexer and Search Head Clusters and are required for deploying applications and configurations to the cluster members and managing the clusters. Any cluster-wide app or configuration setting must come from the Cluster Master in indexer cluster or the Deployer in Search Head Cluster.
The number of search heads in a search head cluster should be odd (3, 5, 7 etc.). This is important especially in a multi-site environment as the search head cluster cannot elect the captain unless a majority of members are available. If both sites have an even number of members and either one of the sites goes down, the cluster will remain functional but all scheduled searches, alarms etc. will be stopped. Therefore, the primary site should always contain the majority of search heads.
If you are hesitant on clustering everything from the start, begin with an indexer cluster and use a single search head for Splunk Web. This will also enhance security in your Splunk environment, as no end users will ever be contacting the indexers directly anymore. Search Head will be the single point of access, which also decides what data users are allowed to access. It is also good practice to do basic security hardening in the load balancer / proxy and terminate TLS there with a certificate signed by a trusted CA.
What else?
There are other instance types for a Splunk Environment, that may become handy when your are considering a fullstack Splunk Enterprise.
Deployment server
A Deployment Server is often mixed with the Deployer, but they serve a totally different purpose. Deployment Server manages Splunk Universal Forwarder configurations and apps, and can also manage any single instance Splunk Enterprise configurations and apps.
If you have 10+ forwarders in your deployment, install a Deployment Server. It will simplify the management overhead substantially.
Heavy Forwarder
Heavy Forwarders are Splunk Enterprise instances, with no indexing capability. A HF can also index data locally if so desired, but then it will require a Splunk Enterprise license.
The use case for heavy forwarders is to be able to provide a single point of log input at a specific site or network, limiting the amount of required firewall openings. It can also be used for data pre-manipulation, like adding a specific field to all data.
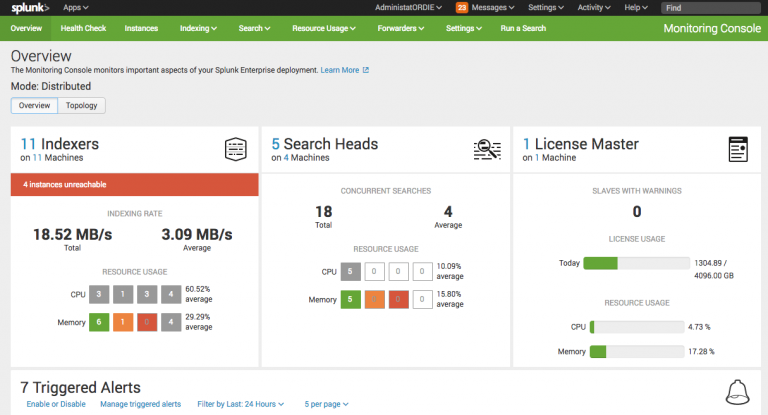
DMC
A DMC (Distributed Management Console) provides a single view of your all of your Splunk Instances and is recommended to be installed always. Depending on access requirements for a DMC, this can normally be activated on the Indexer Cluster Master.
Wrap up
Splunk may seem complex, but the initial configuration is actually very straight forward and simple. If you are serious about Splunk, start with the following
- Configure Indexer Cluster
- Configure Search Head Cluster
- Configure Distributed Management Console
If you have a large number of Forwarders, you definitely want to configure a Deployment Server as well. It will ease up onboarding of new forwarders substantially and with DMC, will provide a single point of monitoring of the forwarders and all of your Splunk Environment.
Happy Splunking!