Managing a Splunk installation can be a complex task, but with proper tools and processes, it will become a lot more approachable. Recently, a customer wanted to have a Splunk environment that they could install and manage with Ansible. So that is what we created. If you are looking for implementing a similar approach, read on for some tips to help your journey.
Planning
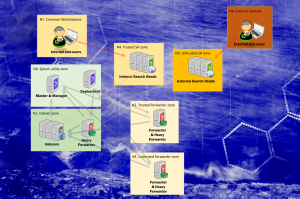
A Splunk Enterprise environment normally consists of multiple servers, that are assigned a specific role. A role could be for example

Indexer

Search Head

Heavy Forwarder
Depending on your environment, there can be multiple servers holding a specific role. Most of the configuration files for different roles are also different, but somewhat identical among the servers within the role. As it happens, ansible also holds a concept of roles, which allows for grouping specific tasks and resources for selected targets. However, using ansible roles will also add complexity as role specific tasks are then divided into role specific playbooks. In a Splunk installation, most of the ansible tasks are identical regardless of the role, but the configurations differ. In the end, we decided to proceed without utilising ansible roles and use group based templates and variables to handle role specific configurations. With a group based approach, we created groups such as
- splunk_deployment
- splunk_sh
- splunk_indexers
- splunk_master
- splunk_shcd
In the inventory, we then placed the servers to the applicable groups and mapped role specific configuration templates to the name of the group. Inventory and templates structure that we ended up with eventually, was the following
- /group_vars
- /all
- /splunk_deployment
- /splunk_indexers
- /splunk_master
- /splunk_sh
- /splunk_shcd
- hosts
- /templates
- /splunk
- /deployment
- /generic
- /master
- /searchhead
- /shcdeployer
- /slave
- user-seed.conf
Within the inventory, each server was assigned a Splunk role, based on the group it was a member of. All Splunk configurations to all servers could then be deployed with two tasks; the first validating the directory structure and the second deploying the templates.
Playbooks
As most of the tasks were to be executed in all of the Splunk servers, we primarily used a single playbook for the installation, except for the firewall rules, which were placed into a separate playbook for better manageability. Also, final monitoring console tuning was placed in a separate playbook as it required for all the servers to be installed first. The primary tasks that were executed were (not necessarily in this order)
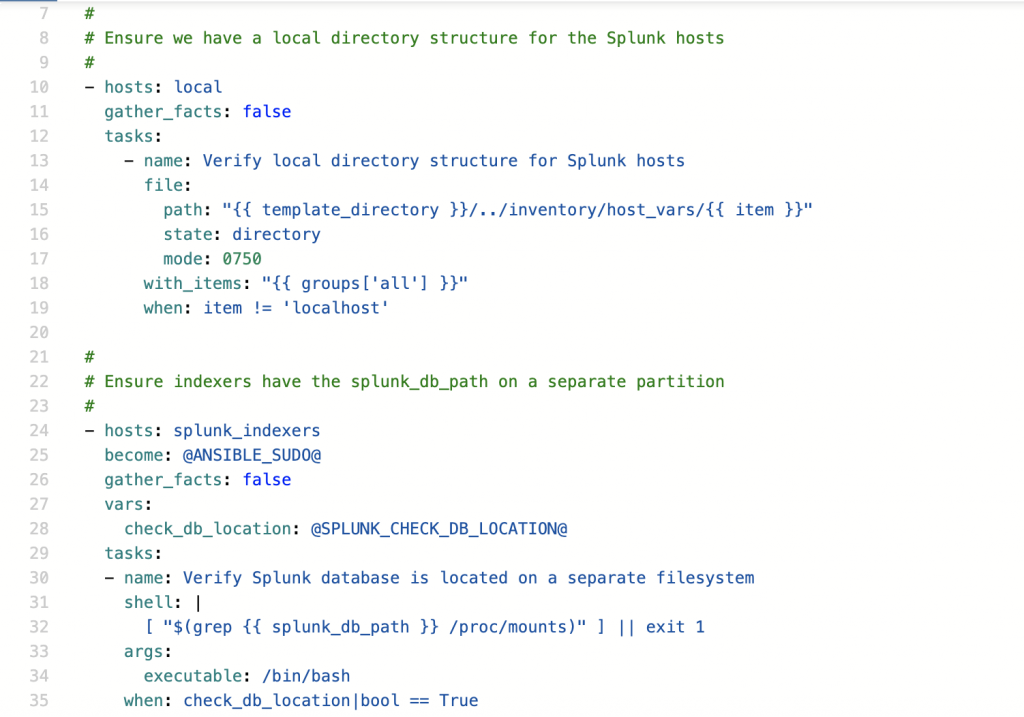
- installation of all the required packages, like splunk and firewalld
- deployment of common configuration files
- encryption of Splunk secrets
- collection of encrypted secrets back to inventory
- deployment of role specific Splunk configurations
- installing Splunk apps
- configuring of kernel parameters
- disabling of transparent huge memory tables and unwanted services
- bootstrapping search head cluster
- registering nodes to monitoring console
- enabling and starting Splunk
- applying indexer cluster configuration
- applying search head cluster configuration
Installation required that we first installed the master and then the other servers due to the servers being automatically registered to monitoring console during installation and the monitoring console was configured in distributed mode in the master. Without monitoring console configuration, everything could have been installed simultaneously.
Handling of secrets
When the installation playbook was run for the first time, all Splunk secrets were read from an ansible vault. The secrets were then encrypted with server specific splunk.secret generated by Splunk and these values were used in the variables written to the Splunk configurations.

The encrypted secrets were then collected back to the inventory to host specific variable files so that on any subsequent playbook runs we would not need to re-encrypt and end up with modified configuration files every time the playbook is run.
Multiple environments
During the development, we of course needed to test in our own environment. To be able to manage different configurations in a more robust way, we created a maven project for the task so we could easily build an identical version with environment specific parameters.

We used environment specific parameters to handle for instance
- ip addresses and names
- indexer cluster members
- search head cluster members
- firewalld rules
- passwords and other secrets
As maven does not properly handle variable lists, we created a local an ansible project to build the actual ansible project for Splunk installation. Maven basicly filled in all environment specific information and then called for ansible to create an ansible project and maven then continued to pack the result to a deliverable package.
Outcome
The end result of using ansible for installing a complex Splunk Enterprise cluster is that the environment can be fully re-built from scratch in about 10 minutes or so, including the vm installations.

In the worst case scenario where everything goes south, the environment can be brought back up in a fairly reasonable amount of time (restoring backups will take some time though). In addition to installation, ansible is of course of great help in configuration management as well, allowing to keep track of any changes and managing the configuration from a central location.